Kubernetes Architecture
We’re going to use an analogy of ships to understand the architecture of Kubernetes.
The purpose of Kubernetes is to host your applications in the form of containers in an automated fashion so that you can easily deploy as many instances of your application as required and easily enable communication between different services within your application.
So, there are many things involved that work together to make this possible. So, let’s take a 10,000 feet look at the Kubernetes architecture.
We have two kinds of ships in this example. Cargo ships, that does the actual work of carrying containers across the sea and control ships that are responsible for monitoring and managing the cargo ships.
The Kubernetes cluster consists of a set of nodes, which may be physical or virtual, on premise or on cloud, that host applications in the form of containers.
This relate to the cargo ships in this analogy. The worker nodes in the cluster are ships that can load containers.
But somebody needs to load the containers on the ships and not just load, plan how to load, identify the right ships, store information about the ships, monitor and track the location of containers on the ships, manage the whole loading process, et cetera.
This is done by the control ships that host different offices and departments, monitoring equipments, communication equipments, cranes for moving containers between ships, et cetera.
The control ships relate to the master node in the Kubernetes cluster.
The master node is responsible for managing the Kubernetes cluster, storing information regarding the different nodes, planning which containers goes where, monitoring the nodes and containers on them, et cetera.
The master node does all of these using a set of components together known as the control playing components.
Master Node
- tasks: Manage, plan, schedule, monitor node
- components: ETCD cluster, kube-apiserver, kube controller manager, kube-scheduler
ETCD
Now, there are many containers being loaded and unloaded from the ships on a daily basis and so you need to maintain information about the different ships, what container is on which ship and what time it was loaded, et cetera.
All of these are stored in a highly available key value store, known as etcd.
Etcd is a database that stores information in a key value format. We will look more into what etcd cluster actually is, what data is stored in it, and how it stores the data in one of the upcoming lectures.
Scheduler
When ships arrive, you load containers on them using cranes. The cranes identify the containers that need to be placed on ships. It identifies the right ship based on its size, its capacity, the number of containers already on the ship and any other conditions such as the destination of the ship, the type of containers it is allowed to carry, et cetera.
So in reality, the kube scheduler identifies the right node to place a container on based on the right containers resource requirements, the worker node capacity, or any other policies or constraints, such as taints and tolerations or node affinity rules that are on them.
Kube Controller Manager
- node-controller: takes care of nodes, responsible for onboarding new nodes to the cluster, handling situations where nodes become unavailable or get destroyed.
- replication-controller: ensures that the desired number of containers are running at all times in a replication group.
kube-apiserver
So, you have seen different components like the different offices, the different ships, the data store, the cranes.
But how do these communicate with each other? How does one office reach the other office and who manages them all at a high level? The Kube API server is the primary management component of Kubernetes. The Kube API server is responsible for orchestrating all operations within the cluster.
It exposes the Kubernetes API, which is used by external users to perform management operations on the cluster, as well as the various controllers to monitor the state of the cluster and make necessary changes as required and by the worker nodes to communicate with the server.
Worker Node
- tasks: host application as containers
- components: kubelet, kube-proxy, container runtimes
Container Runtime
Now, we are working with containers here. Containers are everywhere, so we need everything to be container compatible. Our applications are in the form of containers. The different components that form the entire management system on the master node could be hosted in the form of containers.
The DNS service networking solution can all be deployed in the form of containers. So we need these software that can run containers and that’s the container runtime engine, a popular one being Docker.
So we need Docker, or it’s supported equivalent installed on all the nodes in the cluster, including the master nodes, if you wish to host the controlling components as containers.
Now, it doesn’t always have to be Docker. Kubernetes supports other runtime engines as well like ContainerD and rkt.
kubelet
Now, every ship has a captain. The captain is responsible for managing all activities on these ships. The captain is responsible for liaising with the master ships, starting with letting the mastership know that they’re interested in joining the group, receiving information about the containers to be loaded on the ship and loading the appropriate containers as required, sending reports back to the master about the status of this ship and the status of the containers on the ship, et cetera.
Now, the captain of the ship is the kubelet in Kubernetes. A kubelet is an agent that runs on each node in a cluster. It listens for instructions from the Kube API server and deploys or destroys containers on the nodes as required. The Kube API server periodically fetches status reports from the kubelet to monitor the status of nodes and containers on them.
The kubelet was more of a captain on the ship that manages containers on the ship but the applications running on the worker nodes need to be able to communicate with each other.
For example, you might have a web server running in one container on one of the nodes and a database server running on another container on another node.
How would the web server reach the database server on the other node?
Communication between worker nodes are enabled by another component that runs on the worker node known as the Kube Proxy Service. The Kube Proxy Service ensures that the necessary rules are in place on the worker nodes to allow the containers running on them to reach each other.
Sumarize
So to summarize, we have master and worker nodes. On the master, we have the etcd cluster, which stores information about the cluster.
- We have the cube scheduler that is responsible for scheduling applications or containers on nodes.
- We have different controllers that take care of different functions like the node controller, replication controller, et cetera.
- We have the Kube API server that is responsible for orchestrating all operations within the cluster.
- On the worker node, we have the kubelet that listens for instructions from the Kube API server and manages containers
- Kube Proxy helps in enabling communication between services within the cluster.
etcd
The etcd data store stores information regarding the cluster such as the
- notes,
- pods,
- convicts,
- secrets,
- accounts,
- roles,
- role bindings,
- and others.
Every information you see when you run the kube control get command is from the etcd server. Every change you make to your cluster such as adding additional nodes, deploying pods or replica sets are updated in the etcd server. Only once it is updated in the etcd server is the change considered to be complete. Depending on how you set up your cluster, etcd is deployed differently.
Throughout this section, we discuss about two types of Kubernetes deployments, one deployed from scratch and other using the kubeadm tool.
The practice test environments are deployed using the kubeadm tool, and later in those course when we set up a cluster, we set it up from scratch.
So it’s good to know the difference between the two methods.
Manual Setup
If you set up your cluster from scratch, then you deploy etcd by downloading the etcd binaries yourself, installing the binaries and configuring etcd as a service in your master node yourself.
There are many options passed into the service. A number of them relate to certificates. We will learn more about these certificates, how to create them, and how to configure them later in this course.
We have a whole section on TLS certificates. The others are about configuring etcd as a cluster. We will look at those options when we set up high availability in Kubernetes. The only option to note for now is the advertised client URL.
This is the address on which etcd listens. It happens to be on the IP of the server and on port 2379, which is the default port on which etcd listens. This is the URL that should be configured on the kube API server when it tries to reach the etcd server.
Kubeadm Setup
If you set up your cluster using kubeadm, then kubeadm deploys the etcd server for you as a pod in the kube system namespace. You can explore the etcd database using the etcd control utility within this pod.
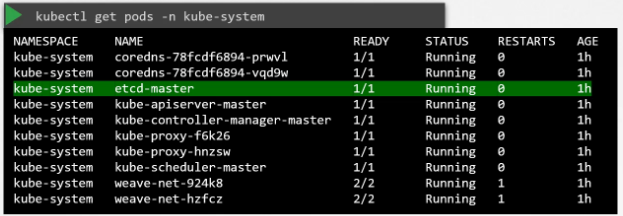
To list all keys stored by Kubernetes, run the etcd control get command like this.
kubectl exec etcd-master -n kube-system etcdctl get --prefix -keys-only